Polynomial Regression from Scratch in Python
ML from the Fundamentals (part 1)
Machine learning is one of the hottest topics in computer science today. And not without a reason: it has helped us do things that couldn’t be done before like image classification, image generation and natural language processing. But all of it boils down to a really simple concept: you give the computer data and the computer then finds patterns in that data. This is called “learning” or “training”, depending on your point of view. These learnt patterns can be extrapolated to make predictions. How? That’s what we are looking at today.
By working through a real world example you will learn how to build a polynomial regression model to predict salaries based on job position. Polynomial regression is one of the core concepts that underlies machine learning. I will discuss the mathematical motivations behind each concept. We will also look at overfitting and underfitting and why you want to avoid both.
The data
The first thing to always do when starting a new machine learning model is to load and inspect the data you are working with. As I mentioned in the introduction we are trying to predict the salary based on job prediction. To do so we have access to the following dataset:
As you can see we have three columns: position, level and salary. Position and level are the same thing, but in different representation. Because it’s easier for computers to work with numbers than text we usually map text to numbers.
In this case the levels are the input data to the model. While we the numbers are already known, the salary is the output data. With this data we will build a model at training time, where both are available. At inference time, we will only have input data. Our job as machine learning engineers is to build a model that outputs good data at inference time.
The input data is usually called $X \in \mathbb{R}^{m \times n}$ where $m$ is the number of training examples, $10$ in our case, and $n$ the dimensionality, or number of features, 1 in our case. A training example is a row in the input dataset which has features, or aspects, which we are using to make predictions.
The output data is called $\vec{y} \in \mathbb{R}^m$, a vector because it typically has only one column.
So in our case
\[X = \begin{bmatrix} 1 \\ 2 \\ 3 \\ 4 \\ 5 \\ 6 \\ 7 \\ 8 \\ 9 \\10 \end{bmatrix} \quad\quad\quad y = \begin{bmatrix} 45000 \\ 50000 \\ 60000 \\ 80000 \\ 110000 \\ 150000 \\ 200000 \\ 300000 \\ 500000 \\ 1000000\end{bmatrix}\]Of course
\[\left \lVert y \right \rVert = m\]In Python:
X = np.array([[1, 2, 3, 4, 5, 6, 7, 8, 9, 10]]).T
y = np.array([45000, 50000, 60000, 80000, 110000, 150000, 200000, 300000, 500000, 1000000])
m, n = X.shape
The $i$th training exmple is $X^{(i)}, y^{(i)}$. The $j$th feature is $X_j$.
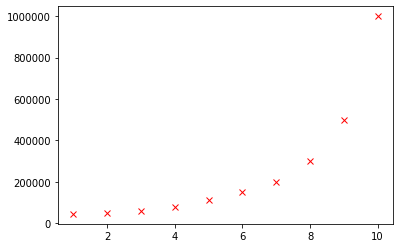
We can inspect our training set in a plot, (since $n = 1$)
plt.plot(X, y, 'rx')
The hypothesis function
To predict output values from input values we use an hypothesis function called $h$, paramaterized by $\theta \in \mathbb{R}^{n+1}$. We will fit $h$ to our datapoints so that it can be extrapolated for new values of $x$.
\[h_\theta(x) = \theta_0 + \theta_1 x_1\]In order to ease the computation later on we usually add a column of $1$’s at $X_0$ giving
\[X = \begin{bmatrix} 1 && 1 \\ 1 && 2 \\ 1 && 3 \\ 1 && 4 \\ 1 && 5 \\ 1 && 6 \\ 1 && 7 \\ 1 && 8 \\ 1 && 9 \\ 1 && 10 \end{bmatrix}\]so that
\[h_\theta(x) = \theta^Tx\]Because these $1$s change the hypothesis independently from the input $x$ it’s sometimes called the bias factor. The bias vector is also the reason $\theta \in \mathbb{R}^{n+1}$ and not $\theta \in \mathbb{R}^n$
# Add a bias factor to X.
X = np.hstack((np.ones((m, 1)), X))
By changing the values of $\theta$ we can change the hypothesis $h_\theta(x)$.
Adding polynomial features
As you will probably have noticed $h$ is a polynomial of degree $1$ while our dataset is nonlinear. This function will always be a bad fit, no matter which values of $\theta$ we use.
To fix that we will add polynomial features to $X$, which, of course, also increases $n$.
By inspecting the plot we learn that adding polynomial features like $(X_j)^2$ could fit our dataset. Nonpolynomial features like $\sqrt{X_j}$ are also allowed, but not used in this tutorial because it’s called “polynomial regression.”
In this model I added 3 additional polynomials, increasing $n$ to $3$.
X = np.hstack((
X,
(X[:, 1] ** 2).reshape((m, 1)),
(X[:, 1] ** 3).reshape((m, 1)),
(X[:, 1] ** 4).reshape((m, 1))
))
You should try adding or removing polynomial features yourself.
Normalization
When we added the features a new problem emerged: their ranges are very different from $X_1$. Every feature $X_j$ has an associated weight $\theta_j$ (more in that later). This means that a small change in a weight associated with a generally large feature has a much bigger impact than the same change has on a generally small feature. This causes problems when we are fitting the values $\theta$ later on.
To fix this problem we use a technique called normalization, defined as
\[X_j := \frac{X_j - \mu_j}{\sigma_j} \quad \text{for } x \text{ in }1\ldots j\]where $\mu_j$ and $\sigma_j$ are the mean and standard deviation of $X_j$ respectively. Normalization sets the mean close to $0$ and the standard deviation to $1$, which always benefits training. Note that we don’t normalize $X_0$ because $\sigma_0 = X_0 - \mu_0 = 0$.
X[:, 1:] = (X[:, 1:] - np.mean(X[:, 1:], axis=0)) / np.std(X[:, 1:], axis=0)
Initializing $\theta$ and making predictions
Before we make a prediction I would like to make a small change to the hypothesis function. Remember $h_\theta(x) = \theta_0 x_0 + \theta_1 x_1$. Note that it only supports one feature, and a bias. We can generalize it as follows:
\[h_\theta(x) = \displaystyle\sum_i^n \theta_i x_i = \theta_0 x_0 + \theta_1 x_1 + \ldots + \theta_n x_n\]Here you can see the link between $X_j$ and $\theta_j$.
Because we will be using the hypothesis function many times in the future it should be very fast. Right now $h$ can only compute one the prediction for one training example at a time.
We can change that by vectorizing it. If we implemented the sum function by looping each $x$ with associated $\theta$, it would take a very long time. We can change that by vectorizing the function. With vectorization you can compute the outputs for an entire matrix, or vector, at once. While you technically compute the same values, good linear algebra libraries such as numpy will optimize the use of the available hardware to speed up the process. A vectorized implementation of $h$:
\[h_\theta(X) = X\theta\]You can validate it works by writing down a few examples. This function takes the whole matrix $X$ as an input and produces the prediction $\hat{y}$ in one computation.
In Python $h_\theta(X)$ can be implemented as:
def h(X, theta):
return X @ theta
Before we can make predictions we need to initialize $\theta$. By convention we fill it with random numbers, but it does not make a difference in this program*.
theta = np.random.random(n+1)
predictions = h(X, theta)
In a graph:

* Random initialization is crucial for symmetry braking in neural networks.
Loss
As you can see our current predictions are frankly quite bad. But what does “bad” mean? It’s much too vague for mathematicians.
To measure we models accuracy we use a loss function. In this case mean square error, or MSE for short. While many loss functions exist, MSE is proven to be one of the best for regression problems like ours. It is defined as
\[J(\theta) = \frac{1}{m}\displaystyle\sum_i^m (h_\theta(x^{(i)}) - y^{(i)})^2\]$J$ is a function of the current state of the model—the parameters $\theta$ which make up the model. It takes our prediction for example $i$, squares it (signs do not matter). This number is the distance from our prediction to the actual datapoint, squared. We take the average of these “distances”.
A vectorized Python implementation:
def J(theta, X, y):
return np.mean(np.square(h(X, theta) - y))
In my case I had a loss of $142\ 911\ 368\ 743$, which may vary slightly as a result of the random initialization.
Regression with gradient descent
We can improve our model, decrease our loss, by chaning the paramters of $\theta$. We do that using an algorithm called gradient descent.
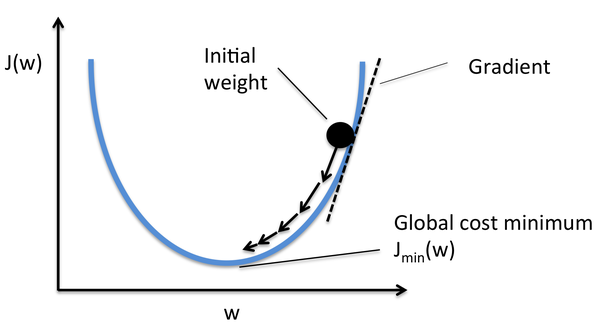
Gradient descent caculates the gradient of a model using the partial derivative of the cost function. This gives the slope of the cost function at our current position ( $\theta$ ) indicating in which direction (gradient) we should move.
This gradient is multiplied by a learning rate, often denoted as $\alpha$, to control the pace of learning*. The result of this multiplication is then substracted from the weights to decrease the loss of further predictions.
Below is a plot of the loss function. The gradient decreases as $J$ approaches the minimum. source
More formally, the partial derivative of $J$ with respect to paramters $\theta$ is
\[\frac{\partial J(\theta)}{\partial \theta_j} = \frac{1}{m}x_j^T(X\theta -y)\]In vectorized form for all $X_j$
\[\nabla J(\theta) = \frac{1}{m}x^T(X\theta -y)\]The gradient descent step is
\[\theta := \theta - \alpha \nabla J(\theta) = \theta - \alpha \frac{1}{m}X^T(X\theta -y)\]We repeat this computation many times. This is called training.
*Choosing a value of $\alpha$ is an interesting topic on itself so I’m not going to discuss it in this article. If you’re interested you can learn more here.
In Python
A typical value for $\alpha$ is $0.01$. It’s interesting to play around with this value yourself.
alpha = 0.01
A gradient descent step can be implemented as follows:
theta = theta - alpha * (1/m) * (X.T @ ((X @ theta) - y))
While training we often keep track of the loss to make sure it decreases as we progress. A training loop is a fancy term for performing multiple gradient descent step. Our training loop:
losses = []
for _ in range(500):
theta = theta - alpha * (1/m) * (X.T @ ((X @ theta) - y))
losses.append(J(theta, X, y))
We train for $500$ epochs.
Looking at our fit again:
predictions = h(X, theta)
plt.plot(X[:, 1], predictions, label='predictions')
plt.plot(X[:, 1], y, 'rx', label='labels')
plt.legend()
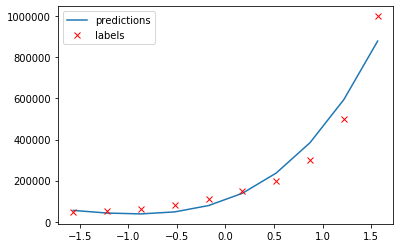
That looks much more promising than what we had before.
Let’s look at how loss decreased during training:
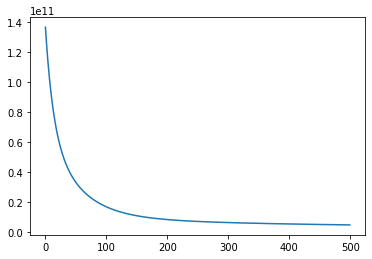
We still have loss of $2\ 596\ 116\ 902$. While this may seem like a huge number, it’s an improvement of almost $98.2\%$. Since we are working with huge numbers in this project we expect the loss to be high. This is one of the reasons you need to be familiar with the data you are working with.
Now that we have fitted $\theta$, we can make predictions by passing new values of $x$ to $h_\theta(x)$.
The normal equation
Even though it is a very popular choice, gradient descent is not the only way to find values for $\theta$. Another method called the normal equation also exists. With this formula you can compute the optimal values for $\theta$ without choosing $\alpha$ and without iterating.
The normal equation is defined as
\[\theta = (X^TX)^{-1}X^Ty\]For more information on where this comes from check out this post.
The biggest advantage of this is you always find the optimal value of $\theta$. Note that this is the best fit for the model ($h$) you built, and might not the best solution for your problem in general.
A drawback of using this method over gradient descent is the computational cost. Computing the inverse $(X^TX)^{-1}$ is $O(n^3)$ so when you have many features, it might be very expensive. In cases where $n$ is large, think $n > 10\ 000$, you would probably want to switch to gradient descent or another training algorithm.
Implementing the normal equation in Python is just a matter of implementing the formula:
theta = np.linalg.pinv(X.T @ X) @ X.T @ y
Note that we use the pseudo inverse instead of the real inverse because a training set might be noninvertable.
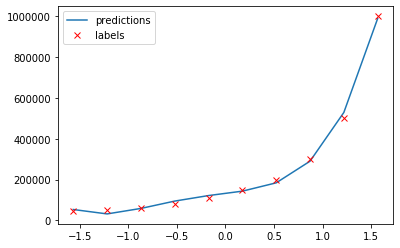
Another risk over using the normal equation is overfitting, which I will cover in the next section.
Overfitting, underfitting, and some tips
Before I wrap up this tutorial I would like to share a little more theory behind machine learning.
Splitting datasets
In this tutorial we used every available training example. In real world applications you would want to split your data into three categories:
- Training data: is the data you train your model on.
- Validation data: is used to optimize hyperparameters, such as $\alpha$ and the number of your epochs. While not very important in regression models, it is a very crucial part of deep learning*. You do not use validation data using training because this subset is designed to optimize hyperparameters instead of weights. Confusing them leads to worse performance.
- Test data: is used to get a sense of how a model would perform in production. This dataset must not be used to improve the model. Changing parameters based on the test dataset will invalidate your ideas about its performce—use the validation set for this.
* Deep learning is a subfield of machine learning.
Feature selection
No two features in a dataset should be dependent on each other. If they were it would put an excessive emphasis on the underlying cause leading to worse accuracy. For example, we could add a “years of experience” feature to our dataset, but “main task” would not be good idea since it’s highly correlated with the job position.
Remember that machine learning models are not magic applications. As a rule of thumb a human must be able to draw the same conclusions given the same input data. The color of someones hair is most likely not related to their salary so adding it to the dataset would only confuse gradient descent. The model could find random correlations though which do not generalize well in production.
Overfitting & underfitting
Underfitting but particularly overfitting are perhaps the biggest problems in machine learning today. To really understand it we have to go back to the fundamental concept of machine learning: learning from data to make predictions about or in the future, using a model.
When your model is fit too specifically to your dataset it’s overfitted. While it has a very low loss, in extreme cases even $0$, it does not generalize well in the real world. The normal equation we used earlier actually overfitted the dataset, because it found a function which passes through our training values very closely, but it does not represent a function of position to salary. For example, notice how it predicts a higher salary for lowest position.
Overfitting can occur when you train your model for too long. Another cause for overfitting is having too many features. To reduce overfitting you should try training your model for fewer epochs, or removing some features. You always want $m > n$.
Underfitting is the opposite of overfitting. When your model is too simple, for example when you try fitting a one degree polynomial to a multidegree dataset, it will underfit.
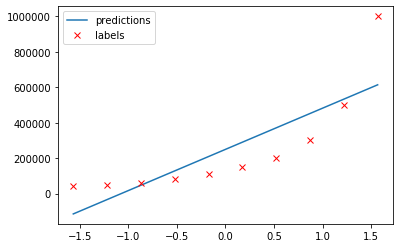
To reduce underfitting you should try adding polynomial features to your dataset. Another cause might be a bad train/test split—you always want your data to be divided equally over your train and test set. For example, we could put some randomly selected job positions in a test set. But if we used only the highest positions for testing, and everything else for training, the model would underfit because it has not seen the full environment it will be used in.
Another technique to reduce overffiting is called data augmentation. With data augmentation you can create more training examples, without actively gathering more data which might not even be available. If you were working with images for example, you could try flipping them horizontally or cropping them.
You can view the complete code for this project here.
What’s next?
This concludes the first post in the “ML from the Fundamentals” series.
Machine learning is not just predicting salaries based on job titles, or even predicting any number based on input data. Predicting values in a continuous space as we’ve done today is called regression, a form of supervised learning because we had labelled data (we know $y$) available at training time.
Another form of supervised learning is classification where your goal is to assign a label to an input. For example, classifying images of handwritten digits would be a classification problem.
Unsupervised learning is the other major subfield of machine learning. Grouping items based on similarity, for example. But also recommendation systems like the YouTube algorithm use machine learning under the hood.
If you are interested in learning more about machine learning, I recommend you check out the series page where I will post all blog posts in this ongoing series.
Thanks for reading
I hope this post was useful to you. If you have any questions or comments, feel free to reach out on Twitter or email me directly at rick_wierenga [at] icloud [dot] com.